
There is no need to introduce OpenAI, the most valuable startup of humanity valued $80 Billions already. Yes, you read it right. The valuation has tripled in under 10 months. As AI is the beacon of hope for the future of mankind, the valuation of OpenAI is bound to go Parabolic for many years to come.
OpenAI Whisper over time developed multiple AI models and Whisper is one of them.
OpenAI Whisper is an advanced Automatic Speech Recognition (ASR) model that converts spoken language to text using heavy duty deep learning models. Whisper was released in September 2022 and has already become a well known natural language processing tool in its own right, praised for its both accuracy and flexibility. Whisper has inspired many open source and in-house commercial software and has already become a beacon in ASR domain.
This post answers some of the common questions about Whisper, what it does and how to think about it before using it for in-house projects.
What is Whisper AI ?
Whisper is an AI/ML model first and foremost, fine tuned for ASR. It contains neural networkmodels that take audio as input and output a transcription. Whisper is made up of multiple models with different sizes ranging from 39M to 1.55B parameters. The higher the parameter count the better the accuracy (higher precision) the trade-off being the compute resources (runtime performance).
What Whisper does Best?
Whisper is extremely accurate and high performing in single and multiple languages and in many adverse audio scenarios such as noisy background etc. As listed in Open ASR Leaderboard, Whisper has average word error rate of 8.06% and is 92% accurate by default. Because it comes in different sizes, developers get to trade-off the compute cost with speed and accuracy.
How Whisper Works ?
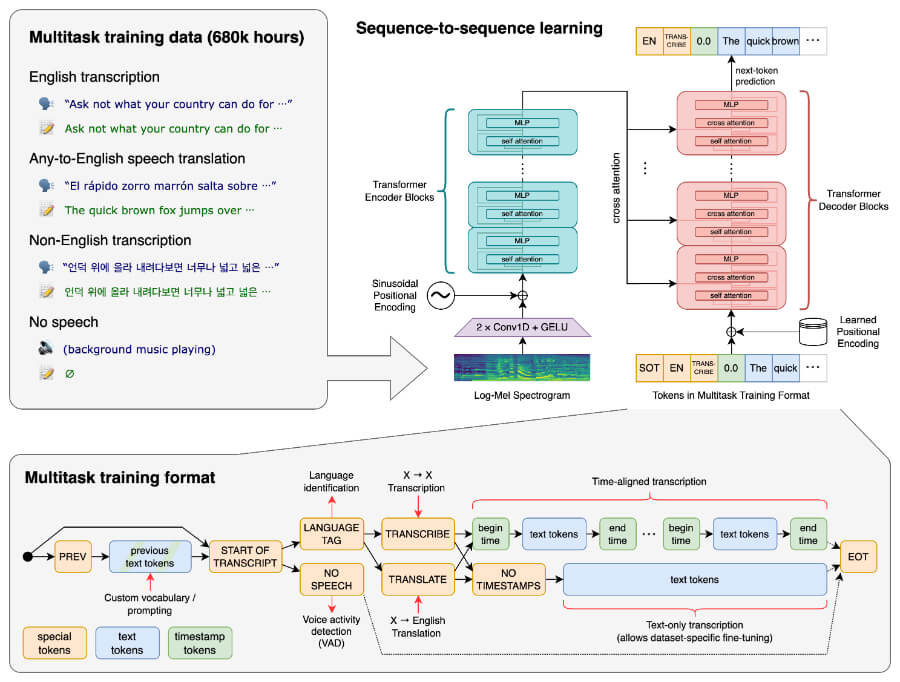
OpenAI Whisper is based on an encoder-decoder Transformer. Transformer is a state-of-the-art model introduced in the paper “Attention is All You Need” in 2017, which can efficiently capture contextualized meanings of words by attending to other words. Whisper encodes the input speech audio in the following two-stage process:
Encoding: It takes input audio split into 30-second segments, computes a log-Mel spectrogram, and feeds it into the encoder to produce a mathematical embedding.
Decoding: A language model is used to [decode] the embedding and predict the next likely sequence of text tokens to produce the final transcription.
Is Whisper Considered Generative AI?
Whisper uses methods from generative AI to infer context and predict missing patches in the transcript, (for example, by understanding the context of entire sentences).
Availability of Whisper API
OpenAI announced the availability of the large-v2 model via API in March 2023. It is faster than the open source model and costs $0.006 per minute of audio transcribed. The Whisper API can be used to get transcriptions in the audio’s source language, or translations in English. Standard audio formats such as m4a, mp3, mp4, and wav are all supported.
Applications of Whisper
Due to the wide applicability of Whisper, it can be deployed in any voice enabled application such as:
Call Center Assistants: For automated interaction with customers via voice.
Virtual Meeting Transcriptions: For transcription in meeting and note-taking software used for various industry verticals such as education, healthcare, and legal.
Media Products: For computation of transcripts and captions for podcasts and video including live stream videos.
Sales Tools: For storing transcriptions in CRM tools used to document meetings with clients.
Limitations of Whisper AI
Whisper has the following limitations:
- File Size and Duration: Limited to 25MB and 30 seconds per upload.
- Accuracy in Professional Audio: Easily makes mistakes if not fine-tuned to domain..
- Advanced capabilities: Realtime transcript, detailed speaker diarization, etc. are not available.
- Scaling: Not easy without AI expertise and heavy hardware investment.
Alternative Solutions to Whisper ASR
Open-Source Alternatives:
- Mozilla DeepSpeech: An open source speech-to-text engine that can be used to train your own models.
- Kaldi: An ASR toolkit for building speech recognition systems with a lot of customization.
- Wav2vec: A self-supervised speech recognition system from Meta AI.
Commercial Alternatives:
- Big Tech: Google Cloud Speech-to-Text, Microsoft Azure AI Speech and AWS Transcribe provide speech to text API for multiple languages with many features.
- Specialized Providers: AssemblyAI, and Deepgram offer very competitive pricing without compromising on performance.
Conclusion
OpenAI Whisper is a powerful ASR system with significant potential for a wide range of applications. By understanding its capabilities and limitations, you can determine whether Whisper is the right choice for your speech recognition needs. For further exploration, consider experimenting with Whisper and evaluating its performance in real-world scenarios.
Resources: